Azure Synapse Analytics For Beginner  Edit
Edit

In this article, we will learn about Azure Synapse Analytics, previously known as Azure SQL Data Warehouse. It is a limitless analytics service from Microsoft Azure. Azure Synapse Analytics is designed to process a large amount of data. Azure Synapse Analytics brings together enterprise data warehousing and Big Data analytics. The process of combining all of the local data sources is known as data warehousing. The process of analyzing streaming data and data from the internet is called big data analysis. It lets you load both relational and non-relational databases from any number of data sources. It unifies all the data. The main function of azure synapse analytics is to get transform and aggregate data into a format suitable for analytics processing, in other words, ingest prepare & serve data. You can perform complex queries over this data and generate reports, graphs, and charts. You can query the data using SQL language
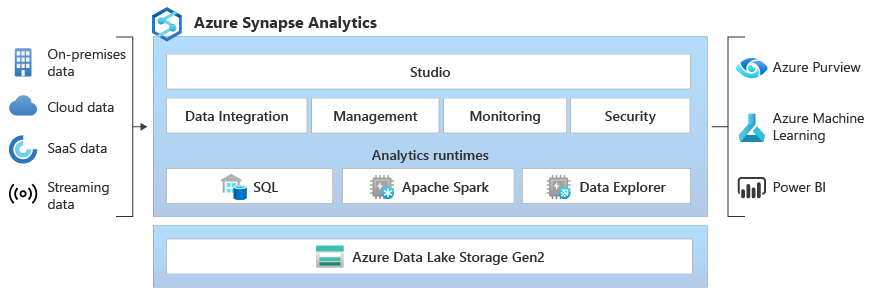
Azure Synapse brings together the best of SQL technologies used in enterprise data warehousing, Spark technologies used for big data, Pipelines for data integration and ETL/ELT, and deep integration with other Azure services such as Power BI, CosmosDB, and AzureML.
Big Data vs Relational Data
In Big Data we store the data into a folder system and it's going to be nonrelational or semi-structured data. In a modern data warehouse, you have relational structured data in the form of tables. Azure synapse analytics merge both Big Data & Data warehousing together and you can query the data using TSQL.
Why use Azure Synapse Analyics
In a modern data warehouse traditionally you had to use a variety of products to ingest, prepare, transform/enrich and model/serve the data. The challenge was there are a lot of products.
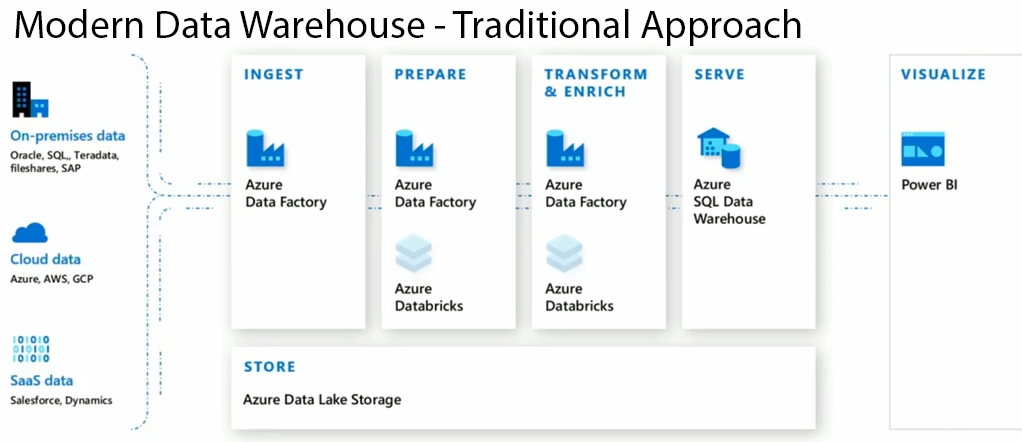
Synapse is fixing the problems by having everything under one single roof

Azure Synapse Analytics Key Tasks
- Ingest
- Explore
- Prepare
- Orchestrate
- Visualize
Azure Synapse analytics allows you to INGEST data from 90 data sources. The data can be ingested into Azure Synapse Analytics using Azure Data Factory pipelines & ADF Mapping Data flows. Ingested data can be stored in Relational Data = SQL Pool (Azure Data Warehouse) , Azure Data Lake Gen 2 (Data Lake), Spark Tables, Cosmos DB.
The Compute has SQL provisioned pools, SQL on-demand pools & Apache spark pool. When a SQL Pool is attached to a relational database, when you create a SQL Pool you create a relational database. Data Lake can also be accessed using provisioned pools. SQL on-demand is a pay per query pricing model It allows you to use T-SQL to access data from the data lake.
Options for compute & how each of these can access the 4 storage mechanisms
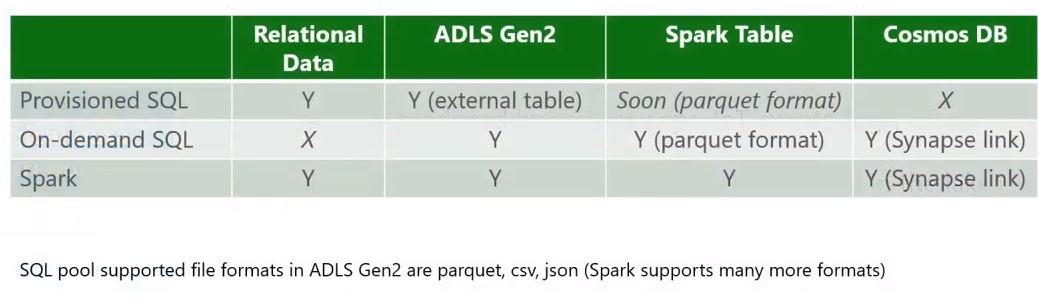
Apache Spark allows you to create spark tables within Azure Synapse Analytics. And spark table can be queried from a notebook as well as using T-SQL from On-demand pools. And we also have Cosmos DB, you can query data from Cosmos DB using T-SQL from the on-demand pool.
Azure synapse analytics also have Power BI integrated within the product for visualization.
Modern Data Warehouse Using Azure Synapse Analytics
A modern data warehouse using azure synapse analytics could look like this.
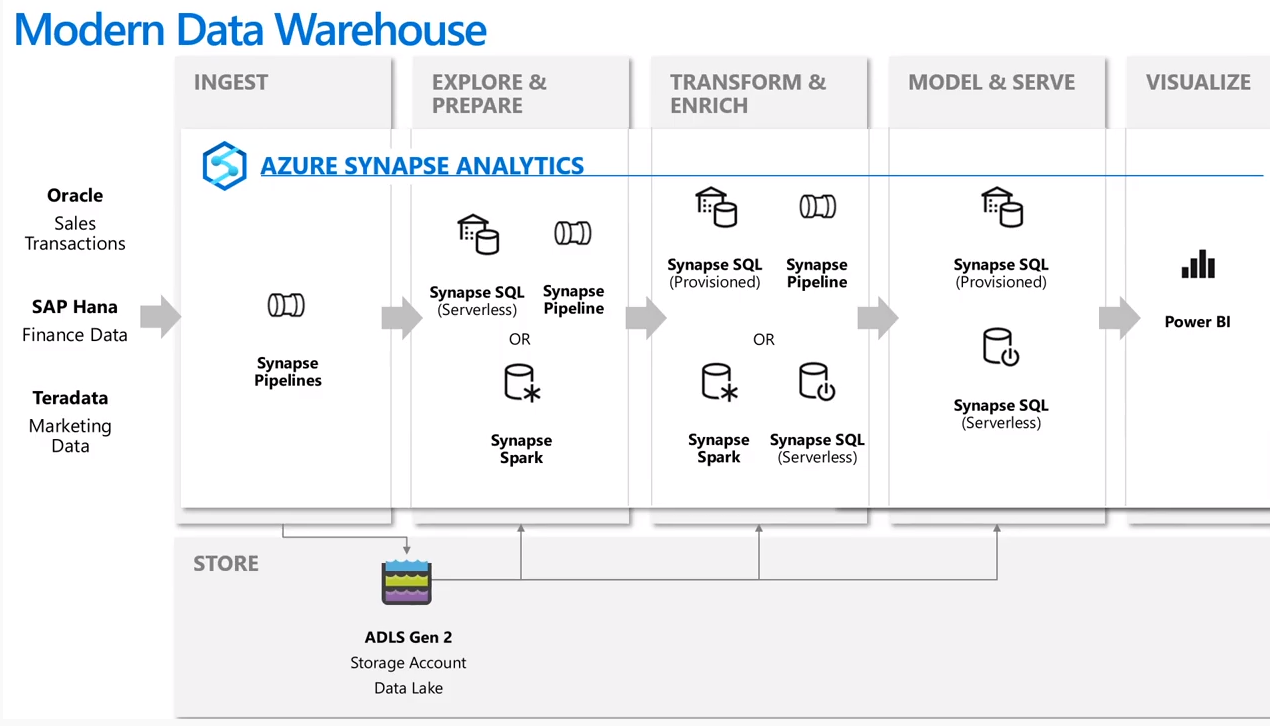
Movement of data using Azure Data Factory
Azure data factory and azure synapse pipeline can be used to manage and orchestrate movement data between data stores.
Azure Data Factory is a cloud-based ETL & data integration service that orchestrates the movement and transformation of data between various data stores and compute resources. You can use a trigger or setup a regular schedule for the batch movement of data. To orchestrating data movement and transforming data at scale you have to create data-driven workflows (called pipelines). You can ingest data from different types of data stores. Azure HDInsight Hadoop, Azure Databricks, and Azure Synapse Analytics can also be used for ETL. Much of the functionality of Azure Data Factory appears in Azure Synapse Analytics as a feature referred to as Pipelines, which enables you to integrate data pipelines between SQL Pools, Spark Pools, and SQL Serverless.
While the Azure Data factory has the primary function of ingesting and transforming the data, It sometimes instructs other services to actual work required on its behalf. ADF can ask data bricks to execute a transformation query and then it provides the pipeline to move the data to the next step or destination.
ETL - Extract Transform Load
Data integration involves collecting, cleaning/transforming and finally, the data is stored in a data platform for analytics your want to perform.
- Extract in the process the data engineer defines the data and its source
- Transform Data transformation operations can include splitting, combining, deriving, adding, removing, or pivoting columns. Map fields between the data source and the data destination. You might also need to aggregate or merge data
- Load Load includes defining the desination and loading the data
Another option is to extract load and then transform ( ELT ). The benefit of ELT is that the data can be stored in oreiginal format and you can use the store data in multiple downstrem systems & Extract load takes lesser time than ELT which helps to free up the data source . There is one more option extract, load, transform, and load (ELTL)
Data-Driven Workflows
Data Source => Injest => Perpare => Transform & Analyse => Publish => Data Cosumption
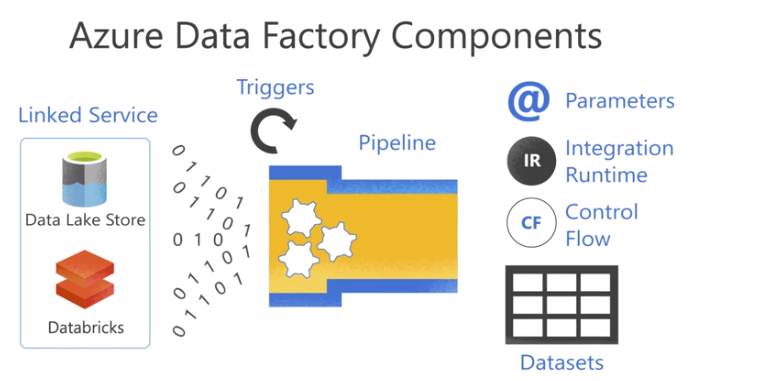
Azure Data Factory Components
- Linked Service defines the connection information needed by data factory to connect to external resources.
- Data sets is a named view of data which points or refences the date within a linked service
- Activities/Pipeline activity eneables you to perform an action on the data. Activities are grouped togather on a component called pipeline which allows you to manage activities as a set
- integration runtime An integration runtime provides the infrastructure for the activity and linked services